
Scraping and Analysing Amazon Reviews

In this post we will use the Python libraries requests and lxml to scrape reviews from an amazon product page.
This data can be used to create datasets for sentiment analysis or other educational or research purposes. If you sell products on Amazon it can even be useful to analyse the reviews to understand what customers like and dislike about your product.
We will scrape the following review information:
author
title
star rating
how many people found this review helpful
publishing date
Rather than scraping the reviews from many products I decided to look at one product with a loooooot of reviews which happens to be the Echo Dot (2nd Generation). It counts more than 60.000 reviews!
THINGS TO CONSIDER IN ADVANCE
There are a lot of different ways how to scrape content from the internet. In this blog post we present a very basic approach which works for our purpose since the amount of data is fairly small and the data format is well formed. If you have a less well formed data format you can consider using BeautifulSoup which is more forgiving but also slower. If you have a more complex task and need to scrape a lot of content you should consider using scrapy.
Things like storing content in a database instead of keeping it the memory, avoiding being blocked by using proxies and using multi-threading to overcome performance bottlenecks become relevant with increasing amounts of data you want to scrape.
SCRAPING THE REVIEWS
Amazon makes it relatively easy to scrape product reviews. You can find all reviews for Echo Dot here.
Using this URL we will get the most recent reviews first and then we just modify the pageNumber parameter in the url to go from one page to the next.
Before requesting the data from Amazon go to this page and get your browser's' user agent string to avoid being blocked by Amazon.
Now we can get the content of the first review page:
from lxml import html import requestsamazon_url = 'https://www.amazon.com/product-reviews/B01DFKC2SO?pageNumber=1&sortBy=recent'user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'headers = {'User-Agent': user_agent}page = requests.get(amazon_url, headers = headers)parser = html.fromstring(page.content)
Next we have to find the nodes of the reviews to extract them from the page. For that you open the review page in your Chrome browser, right-click on a review and select inspect:
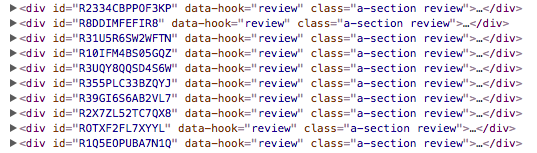
Passing the XPATH to the parser will return the list with the reviews on that page:
xpath_reviews = '//div[@data-hook="review"]'reviews = parser.xpath(xpath_reviews)
Do the same with the elements of a review to get the XPATHs of the author, title and so on.
xpath_rating = './/i[@data-hook="review-star-rating"]//text()' xpath_title = './/a[@data-hook="review-title"]//text()'xpath_author = './/a[@data-hook="review-author"]//text()'xpath_date = './/span[@data-hook="review-date"]//text()'xpath_body = './/span[@data-hook="review-body"]//text()'xpath_helpful = './/span[@data-hook="helpful-vote-statement"]//text()'
Now we can loop over the reviews and extract the information from each review into a dictionary and append it to a dataframe:
for review in reviews: rating = review.xpath(xpath_rating) title = review.xpath(xpath_title) author = review.xpath(xpath_author) date = review.xpath(xpath_date) body = review.xpath(xpath_body) helpful = review.xpath(xpath_helpful) review_dict = {'rating': rating, 'title': title, 'author': author, 'date': date, 'body': body, 'helpful': helpful} reviews_df = reviews_df.append(review_dict, ignore_index=True)
After that we modify the URL and scrape the next page.
Now we have to do some data cleaning in order to convert the star ratings to integers and the publishing date to datetime format. After that we can start exploring the data.
DATA EXPLORATION
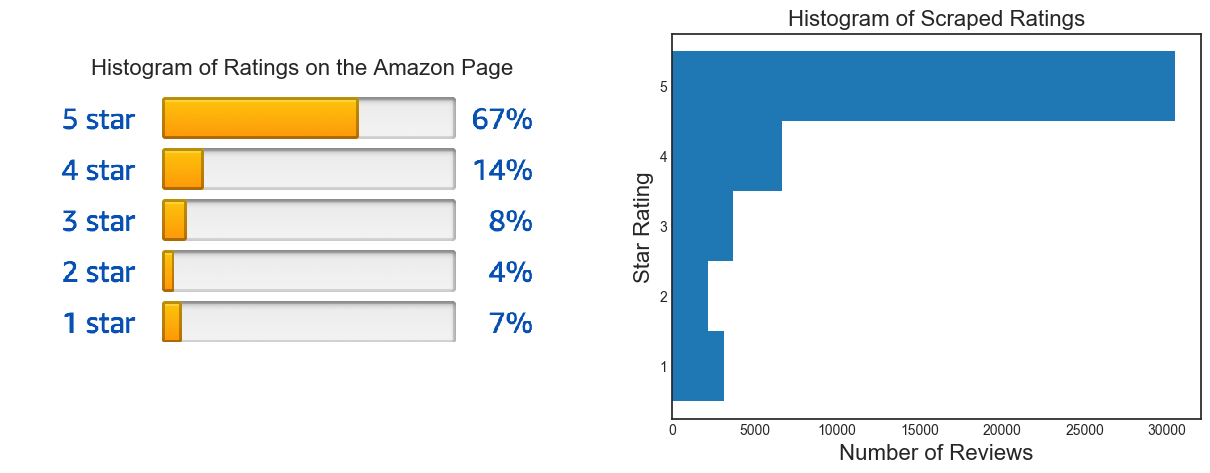
Let's look at some histograms first. The plot of the star ratings should be the same as on the Amazon page if the scraping went as expected:
Now the length of the reviews:
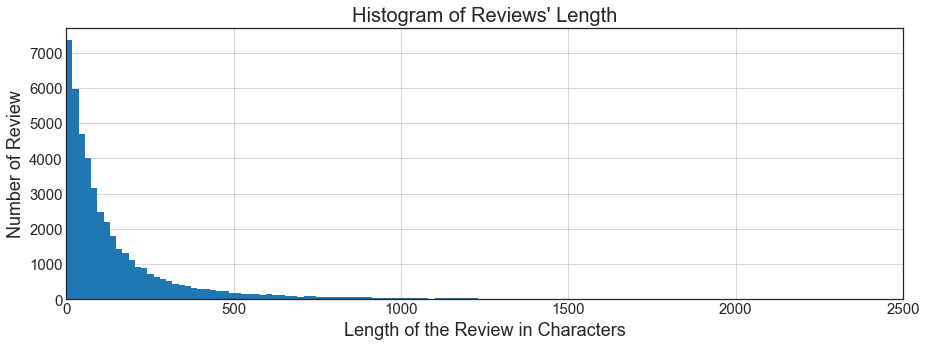
As expected most of the reviews a very short. Amazom.com does not have a restriction for a minimum length of a review. The longest review is longer than 18K characters which is way longer than this blog post.
The picture becomes clearer if we look at the logarithm of the length:
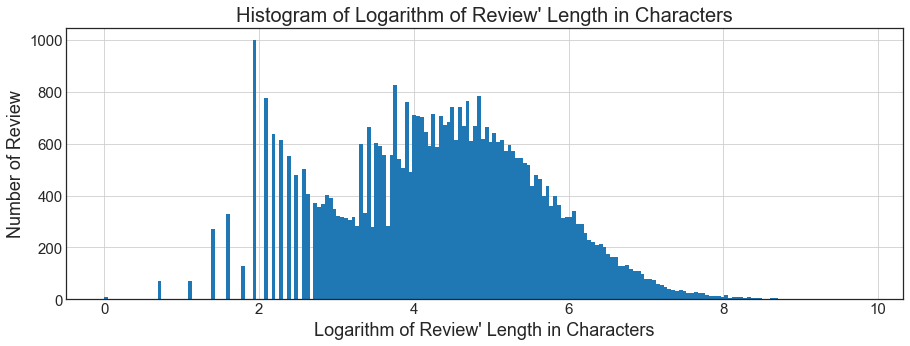
The most frequent length (the mode of the histogram) is 7. This is because there is a huge number of reviews which are simply "love it" and "awesome"
The 2nd generation of Echo Dot was released in October 2016. The histograms of review dates confirms that we scraped even the oldest reviews:
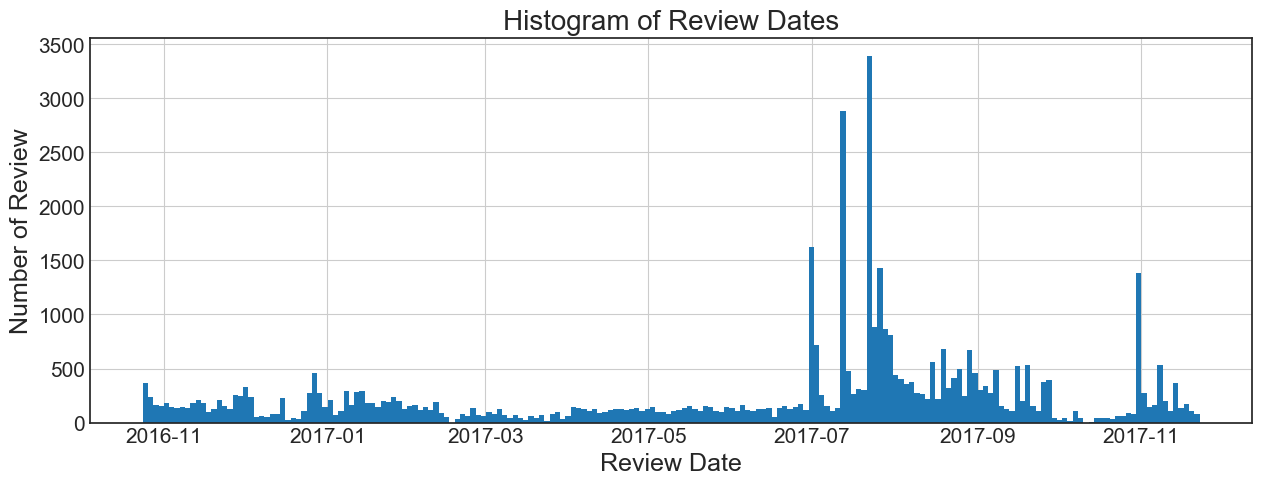
I'm not quite sure about the spikes in July 2017. Maybe they are related to the huge success of the Amazon Prime Day and the fact that Echo Dot was the most popular Product during the Prime Day.
Let's now look at the correlation between the length of the review and the number of people who found it helpful. Since both of these variables have a very long tail we calculate the logarithm from them.
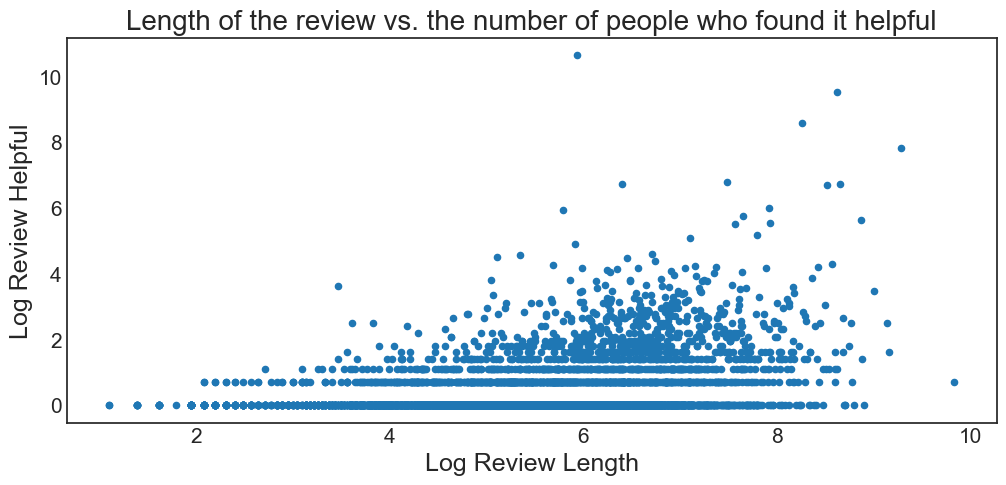
The results look as expected, longer reviews are found more helpful than short ones.
Next we can a look at word clouds generated from the reviews. We split the reviews in 2 categories: Rating "1, 2, or 3 stars" and "4 or 5 stars". To count the word co-occurrences in the reviews we can use the CountVectorizer from the sklearn library and a simple word cloud generator.

Single word counts
We cannot learn much just from looking at the word frequencies since "like" in the bad reviews can also come from "don't like". Instead we can look at the co-occurrences of bigrams and trigrams, which can also be generated by the CountVectorizer.

Bigrams

Trigrams
Now the pictures become more clear - apparently a lot of customers complain about poor sound quality, wifi connectivity and customer service. The positive reviews contain a lot of generic phrases such as "best thing ever" and "works great". Also among popular bi- and trigrams are "bought prime day" and "prime day" which may support the hypothesis that the spikes in the histogram of reviews per day are related to the Prime Day.
I hope this was helpful - now try it out yourself on some other product and post your findings in the comments! :-)